ChatGTP is an amazing technology - you can use it for all sorts of things, from generating code to writing poetry. You can even make a cocktail bot:
You can watch a video explanation here - or read on if you prefer.
But it has come in for some criticism when it comes to factual information, it’s often accused of getting things wrong, making facts up, or even sometimes outright lying and misleading the user.
Let’s try and provide an intuitive explanation as to why ChatGPT doesn’t seem to know what is true and what is false - why does it often seem to “hallucinate” things that don’t exist.
First off, what are we actually talking about? ChatGPT is built on top of a Large Language Model or LLM.
The particular Large Language Model used in ChatGPT is a Generative Pre-trained Transformers.
The model is trained on a huge amount of text - in the case of GPT3, 45 TB of text data was used.
During this pre-training, the language model develops a broad set of skills and abilities. Once training is complete, it can use these abilities on new tasks.
To use the trained model you feed in a prompt consisting of a series of words. The model then predicts the next word. This process is repeated until the model runs out of words.
We can pretend to be a language model - imagine the passage:
“The cat sat on the…”
There are a couple of potential words that are likely to follow this - as humans, we know that it would probably be “mat”, or “lap”, or maybe if we’re feeling a bit whimsical “hat”.
You could imagine how you could build a simple language model.
First, you would need to know how to start a sentence, what is the most likely word that would be at the start of a sentence?
You could take all the words in your vocabulary and count how many times each one is used at the start of a sentence and that would let you pick the most likely word.
For the second word you could count how many times two words occur together.
For the third word you could count how many times three words occur together.
And so on until you have built a large enough table of probabilities that you could generate a fairly long piece of text.
The problem is that for any reasonably long piece of text, this table would be huge.
Apparently, most native speakers have a vocabulary that ranges from 20,000-35,000 words.
Even taking the lower range for this we end up with a table that explodes in size. Every time we add a new word we need to multiply the size of our table by 20,000. It increases exponentially.
After just 20 words we would need a table containing more than one hundred septenvigintillion entries - that’s 10 with 86 zeros after it. To put that into perspective, that’s 10,000 times more than all the atoms in the known universe. And that’s just using our very conservative 20,000-word vocabulary.
This exponential behaviour is why we can use three or four random words as a strong password. With 3 words there are over 8 million million possible combinations that a hacker would need to try.
There are some issues with using words in a Large Language Model. There are simply too many of them. Although the average person may only use 20,000-35,000 words there are actually many more - around 500,000 to 1 million.
The GPT models get around this by using tokens instead of words. In total there are 50,257 tokens in the GTP vocabulary. There’s a really nice online tool that you can use to see how it breaks text up into tokens here.
For example, the phrase “Elephant carpaccio is not something you should eat” gets broken up into 11 tokens even though it only contains 8 words. The longer words “elephant” and “carpaccio” are turned into multiple tokens.

Using tokens lets us encode a lot more words compared to just using a fixed vocabulary.
Under the hood, the model doesn’t actually work on “tokens”. Each token is actually turned into something called an embedding. An embedding is pretty simple, it’s just a bunch of numbers (a vector) that represents the token. For the most capable GPT3 model, each token is represented by 12288 numbers.
These “embeddings” are learnt by the model during training and help to represent the meaning of each token. Tokens with similar meanings will end up with similar embeddings. These embeddings are actually really powerful just by themselves and there are a lot of interesting applications for them.
However, even if we grouped similar tokens together, they are still different. We still have a very large number of inputs coming into our model, so we still have the problem of our probability table exploding exponentially.
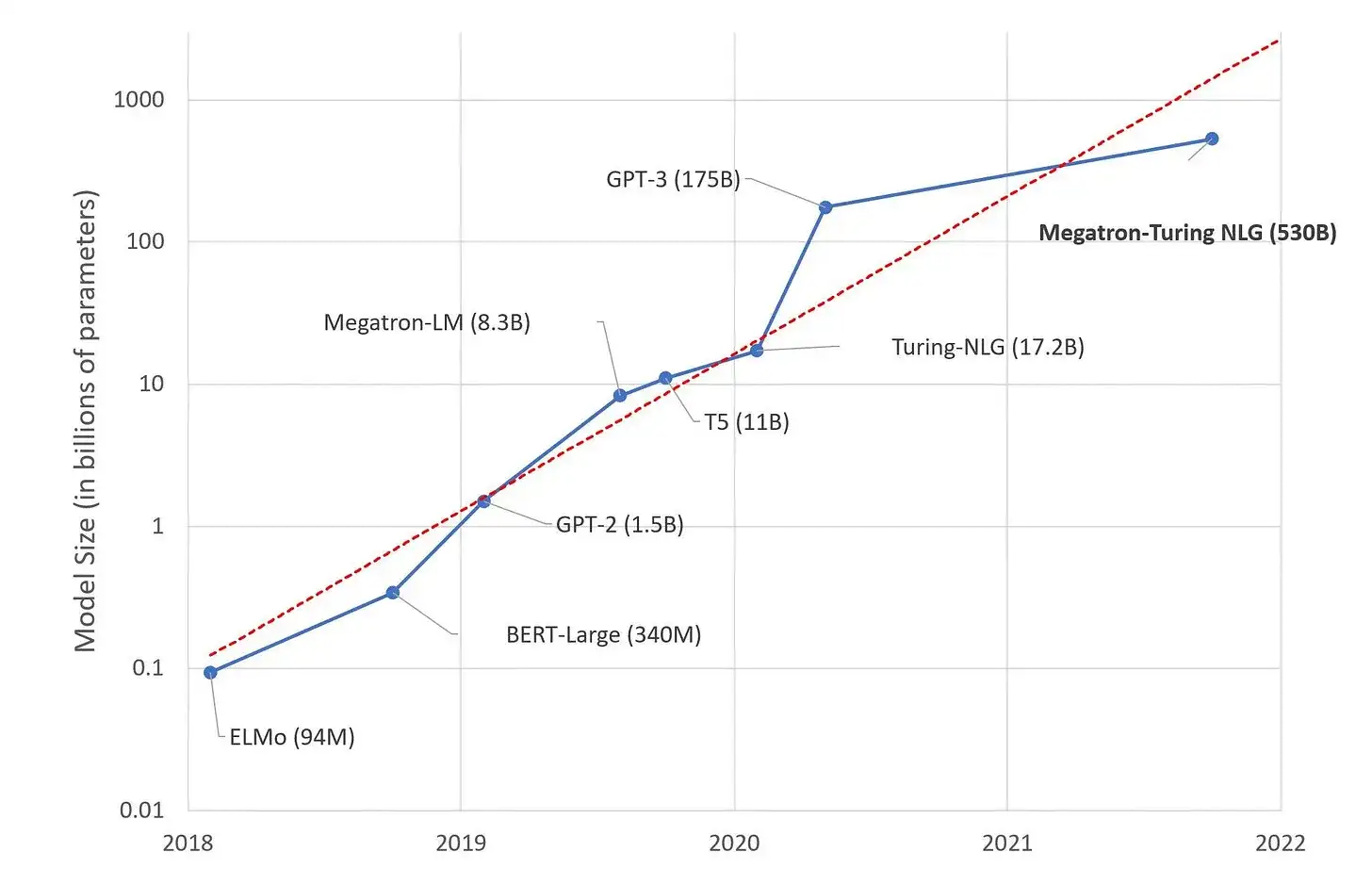
The GPT3 model only has 175 billion parameters and it can have an input of up to 4096 tokens - there’s no way you could store every possible combination of tokens in it.
The model has to learn an approximation of the probabilities. There’s a “lossy” compression of the real world happening.
We’re all familiar with lossy compression from looking at JPEG images. There’s a reason why professional photographers like to shoot their pictures in RAW format - they want to avoid losing any information from their pictures.

So, we know that the model is actually learning an approximation of the real world. Obviously, the more parameters the model has the better this approximation will be, but it will never be perfect.
It’s also simply learning to approximate probabilities of combinations of words. It’s not storing facts or algorithms.
This means that when you ask it a factual question, the information simply may not exist in the model. However, what does exist in the model is an approximation for what is the most likely answer. (strictly speaking, it’s the most likely combination of tokens that would follow the tokens in your question).
You may be lucky and it may be that the facts you are looking for are the most likely tokens - but you may be unlucky and the most likely tokens simply look correct.
One of the amazing things about these models is that they can do anything useful at all. And this is why these Large Language Models are such a breakthrough. Previously to get something useful you would need to train a model for a particular use case. Now, with these very large models, you can just train the model on a whole bunch of text and it can be used to solve multiple problems.
What can we do about this?
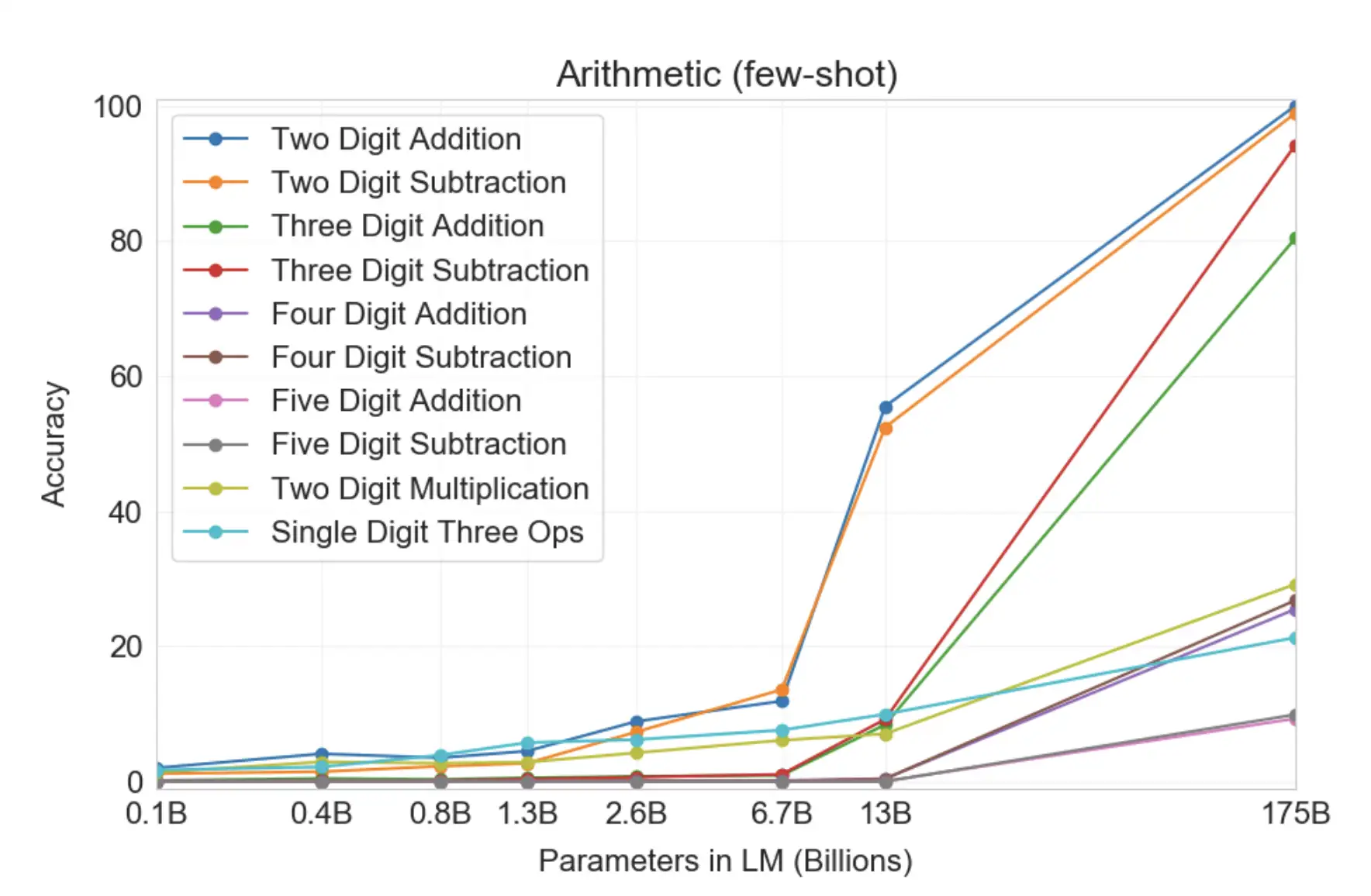
The actual GPT3 paper is surprisingly useful, it does go into great detail about how the model performs. All the people complaining about how bad ChatGPT is at arithmetic should really go and read the paper and see what the authors said it was capable of (it can just about do simple addition and subtraction on small numbers).
There are several ways to help the model behave in more useful ways. You’ll probably have heard people mention these - but these people often assume that you already know what they are talking about…
Zero-Shot Learning
The default way of using the model is called “zero-shot” learning. We just give the model a prompt (e.g. “You are an AI assistant”) and hope for the best. This works surprisingly well!
You can also make the prompt very detailed. One very interesting approach is to look at the question the user is asking and then find matching text from a database of facts (e.g. user manuals, technical documentation). You then feed these facts in as part of the prompt - if you do this right, the model will use your information to answer the question.
One Shot Learning
This is the same as zero-shot learning, but you provide an example to the model so that it knows more about what you are trying to do. An example might be a translation bot. You could give it a prompt as follows:
You are a translation tool.
English: Hello
Spanish: Adios
Few Shot Learning
Exactly the same as one-shot learning, except that you give the model multiple examples.
Fine-tuning
This is more complicated and actually involves taking a trained model and then tweaking its parameters by training it on your own text.
This is a very powerful technique as most of the hard work has already been done. The model has learned about language and you now feed it the facts that you want it to memorise.
What’s coming next
Prompt engineering is a new field - we’re still learning how to get the most out of these Large Language Models - what we’ve seen so far are just baby steps.
There are also new models coming soon that have even more parameters - these have huge potential. It’s going to be a wild ride!